
Definition:
AIクラスタ向けの光接続とは、生成AIや大規模機械学習のために構築された多数のGPUサーバを、光ファイバと高速光トランシーバで相互接続するネットワークのことである。
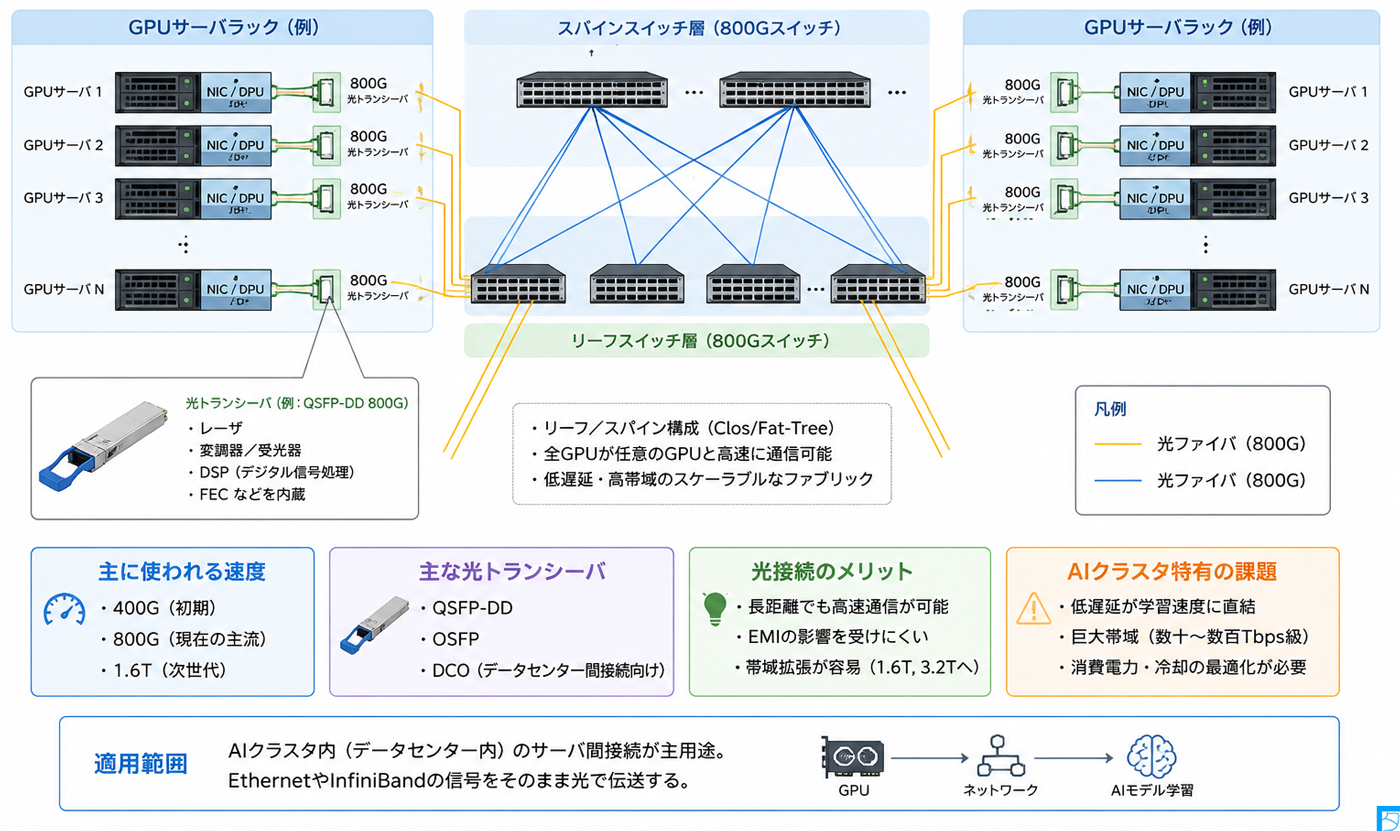
従来の企業ネットワークでは、サーバ間通信は比較的少量であった。しかしAIクラスタでは、学習中にGPU同士が巨大なテンソルを頻繁に交換するため、ネットワーク帯域が計算性能そのものを左右する。
大規模言語モデル(LLM)の学習では、数千〜数万台のGPUが同時に動作する。各GPUは、勾配(gradient)の同期、モデルパラメータの更新、アクティベーションの転送などを行うため、サーバ間で膨大なデータをやり取りする。
この通信量は、従来のCPU中心データセンターより桁違いに大きい。そのため、銅線(DACケーブル)だけでは距離・消費電力・帯域の面で限界があり、光ファイバが不可欠となる。
AIクラスタにおける光ネットワークの発展は、単純な総帯域の増加として捉えるよりも、光モジュールやスイッチに実装されるSerDes(Serializer/Deserializer)技術の進歩として理解する方が本質的である。実際には、400G・800G・1.6Tといった総帯域は、レーン当たりの伝送速度向上と、それを束ねるレーン数の組み合わせによって実現されている。
AIクラスタにおいては、GPUの演算性能とネットワーク帯域との均衡がシステム全体の性能を左右する。大規模分散学習では勾配同期やモデルパラメータ交換によって膨大な通信が発生するため、光インターコネクトには継続的な帯域拡張が求められる。その発展は、総帯域の増加としてだけではなく、光モジュールやスイッチに実装されるSerDes技術の進歩として理解することができる。以下の表は、その技術的系譜をレーン世代の観点から整理したものである。
| 光インターコネクト世代 | 代表的な総帯域 | 代表的レーン構成 | SerDes技術 | 技術的位置付け | 主な適用領域 |
|---|---|---|---|---|---|
| 100G級レーン世代 | 400G | 8×50G 4×100G | 56G / 112G PAM4 | AI・HPC向け光インターコネクトの普及を支えた世代である。 従来の25G級レーンから100G級レーンへの移行期に位置付けられ、 大規模GPUクラスタの構築を現実的なものとした。 | 中規模~大規模GPUクラスタ、 Spine-Leafネットワーク、 データセンター相互接続(DCI) |
| 200G級レーン世代 | 800G | 8×100G 4×200G | 112G PAM4 | 数千~数万GPU規模の分散学習環境を想定した世代である。 帯域密度の向上により、AIモデルの大規模化とクラスタの高密度化を支える基盤技術となった。 | 大規模AI学習基盤、 HPCシステム、 クラウド事業者のバックエンドネットワーク |
| 400G級レーン世代 | 1.6T | 8×200G | 224G PAM4 | 帯域密度と電力効率のさらなる向上を目的とする世代である。 GPU数万台規模を超える超大規模分散学習環境や、 エクサスケール級計算基盤における通信ボトルネックの緩和を目的としている。 | 超大規模AIクラスタ、 エクサスケール計算基盤、 高密度GPUラック間接続 |
AIクラスタでは、GPUサーバ、スイッチ、ストレージ装置などを相互接続するために高速な光トランシーバが利用される。光トランシーバは、サーバやスイッチ内部の電気信号を光信号へ変換して送信し、受信した光信号を再び電気信号へ変換する役割を担う。AIクラスタ向けの光インターコネクトでは、主にQSFP-DD(Quad Small Form-factor Pluggable Double Density)およびOSFP(Octal Small Form-factor Pluggable)が採用されている。
QSFP-DDは高いポート密度と幅広い互換性を特徴とし、400Gおよび800Gクラスの光モジュールで広く利用されている。一方、OSFPはより大きな筐体を持ち、高消費電力の光モジュールを収容しやすいことから、高帯域化が進むAIクラスタで採用例が増加している。また、データセンター間接続(Data Center Interconnect: DCI)では、DCO(Digital Coherent Optics)が利用されることがある。DCOはコヒーレント光通信技術を用いて長距離伝送を実現するものであり、都市間あるいは広域に分散したデータセンターを接続する際に重要な役割を果たしている。
これらの光モジュール内部には、半導体レーザー、光変調器、受光器、DSP(Digital Signal Processor)などの高度な電子・光学部品が集積されている。DSPは誤り訂正や信号補償などを担当し、高速かつ安定した通信を実現するための中核技術となっている。
AIクラスタでは、従来のデータセンターと比較して極めて厳しいネットワーク要件が課される。特に重要なのが低遅延である。大規模分散学習ではGPU間で頻繁に勾配同期やパラメータ交換が行われるため、わずかな通信遅延の増加であっても学習時間全体に大きな影響を与える。そのため、ネットワークには高帯域であるだけでなく、極めて低い遅延特性が求められる。
また、AIクラスタでは巨大な通信帯域が必要となる。数千台から数万台規模のGPUを接続する環境では、ネットワーク全体として数十Tbpsから数百Tbps級のスイッチング容量やファブリック帯域が要求される。このため、光インターコネクトは単なる配線技術ではなく、システム全体の性能を左右する重要な要素となっている。
さらに、消費電力も大きな課題である。高速光モジュールは内部に複雑な光学系やDSPを搭載しているため、1個当たり10~20W以上の電力を消費することがある。大規模クラスタでは数千個単位で光モジュールが使用されるため、その消費電力は無視できない規模となる。
加えて、発熱への対応も重要である。高密度にGPUやネットワーク機器を収容したAIクラスタでは、ラック当たりの消費電力が数百kW級に達する場合もあり、空冷のみならず液冷技術の導入が検討されることもある。光モジュール自体の発熱も含めて、冷却設計はシステム全体の安定運用を左右する重要な要素である。
このような環境において光通信が採用される理由は明確である。第一に、光ファイバは長距離であっても高い伝送速度を維持できるため、ラック間、列間、さらにはデータセンター間を高速に接続できる。第二に、光信号は電磁波による干渉を受けにくく、EMI(Electromagnetic Interference)に対して高い耐性を持つ。そのため、高密度に機器が配置された環境でも安定した通信品質を維持できる。第三に、光通信は帯域拡張性に優れている。レーン当たりの伝送速度向上や波長多重技術の導入によって、400Gから800G、さらに1.6Tや3.2Tへと発展させることが可能であり、将来の大規模AIシステムにも対応できる拡張性を備えている。
このように、AIクラスタにおける光トランシーバは単なる信号変換装置ではなく、低遅延・大容量・高信頼性を実現するための基盤技術として位置付けられている。
Mathematics is the language with which God has written the universe.