
最小二乗法[Ordinary Least Squares;OLS]の目的は複雑な構造を持つデータを少数の式の重ね合わせ[線形結合,linear combination]で表現することにあります.このように大量のデータを少数のデータで表現することを音声や画像に応用する場合はデータ圧縮[data compression]と呼ばれます.最小二乗法はデータ圧縮の一つともいえます.
$y$ と $x$ という2つのデータがあって,いま,$x$ の値が分かっている場合に,$y$ の値を推測(予測)するということを考えてみます.$x$ と $y$ というデータは次のように表されます.\[\left(\begin{array}{cc}x_{1}\ y_{1}\\x_{2}\ y_{2}\\\vdots \ \vdots\\x_{N}\ y_{N}\end{array}\right)\]$x$ が与えられたとき,$y$ の条件付き期待値 $E(y|x)$ は,$y$ の平均2乗予測誤差を最小にする $x$ の関数となります.
一般的にいうと,$E(y|x)$ は $x$ の非線形関数になります.しかし,ここでは簡単に次のような線形関数を考えることとします.\[f(x)=\beta_{0}+\beta_{1}x\]そうすると,平均2乗予測誤差は,\[E\{(y-b_{0}-b_{1}x)^{2}\}\]と表されます.
この平均最小2乗予測誤差を最小化します.
ここで新たに,\[y=\beta_{1}+\beta_{2}x+u\]となる $u$ という変数を定義します.
この式を,平均2乗予測誤差の\[E\{(y-\beta_{0}-\beta_{1}x)^{2}\}\]に代入します.
\[E(u)=0,E(xu)=0\]という関係を利用すると,\[\begin{align}E\{(y-\beta_{0}-\beta_{1}x)^{2}\}&=E\{u+(\beta_{1}-b_{1})+(\beta_{2}-b_{2})x\}^{2}]\\&=E(u^{2})+[\beta_{1}-b_{1}\ \beta_{2}-b_{2}]\left[\begin{array}{cc}1\ E(x)\\E(x)\ E(x^{2})\end{array}\right]\left[\begin{array}{c}\beta_{1}-b_{1}\\\beta_{2}-b_{2}\end{array}\right]\end{align}\]となります.
さらに,\[x=[1 \ x]'\]とおくと,\[\left[\begin{array}{cc}1\ E(x)\\E(x)\ E(x^{2})\end{array}\right]=E[xx']\]となります.
つまり,\[\begin{align}E\{(y-\beta_{0}-\beta_{1}x)^{2}\}&=E\{u+(\beta_{1}-b_{1})+(\beta_{2}-b_{2})x\}^{2}]\\&=E(u^{2})+[\beta_{1}-b_{1}\ \beta_{2}-b_{2}]\left[\begin{array}{cc}1\ E(x)\\E(x)\ E(x^{2})\end{array}\right]\left[\begin{array}{c}\beta_{1}-b_{1}\\\beta_{2}-b_{2}\end{array}\right]\\&=E(u^{2})+[\beta_{1}-b_{1}\ \beta_{2}-b_{2}] E(xx') \left[\begin{array}{c}\beta_{1}-b_{1}\\\beta_{2}-b_{2}\end{array}\right]\end{align}\]となります.
ここで,任意の2次元ベクトル $a$ に対しては,\[a'xx'a=(a'x) \geq 0\]となり,\[a'E(xx')a=E\{(a'x)^{2}\}\]となるので,\[E(xx')\]は非負定符号行列[nonnegative definite matrix]であり,固有値は全て非負になります.
また,$E(xx')$ の行列式,\[|E(xx')|=E(x^{2})-\{E(x)\}^{2}=var(x)\]となるため,$var(x) > 0$ ならば,$E(xx')$ は正則ということになります.
以上の結果から,\[E\{(y-\beta_{0}-\beta_{1}x)^{2}\}=E(u^{2})+[\beta_{1}-b_{1}\ \beta_{2}-b_{2}] E(xx') \left[\begin{array}{c}\beta_{1}-b_{1}\\\beta_{2}-b_{2}\end{array}\right]\]の右辺第2項は,\[b_{1}=\beta_{1},b_{2}=\beta_{2}\]のときを除いて常に正となります.
よって,$\beta_{1},\beta_{2}$ が最小解であることが分かりました.
この解は最良線形予測[best linear prediction]と呼ばれますが,このように,条件付き期待値とは一般には一致しません.
最小化の1階条件の式を展開すると,合成関数の微分から,\[\frac{\partial S(\beta_{1},\beta_{2})}{\partial \beta_{1}}=2(y-\beta_{1}-\beta_{2}x)=0\]\[\frac{\partial S(\beta_{1},\beta_{2})}{\partial \beta_{1}}=2(y-\beta_{1}-\beta_{2}x)x=0\]となります.
両辺を $2$ で割ると,\[\begin{array}y-\beta_{1}-\beta_{2}x&=0\\(y-\beta_{1}-\beta_{2}x)x&=0\end{array}\]
ここで,先ほどと同じように,\[X=[1 \ x]'\]とおくと,\[\begin{array}(y-\beta_{1}-\beta_{2}x)&=0\\(y-\beta_{1}-\beta_{2}x)x&=0\end{array}\]という2つの式は1つにまとめることが出来て,\[X'(y-X\beta)=0\]と表すことが出来ます.この関係式を正規方程式(normal equation)と言われます.
正規方程式[normal equation]を変形すると,\[X'y-X'X\beta=0\]となり,さらに変形すると,\[X'X\beta=X'y\]となり,$X$ の階数が列数に等しいとすると,$X'X$ は正則であって逆行列が存在します.
従って,\[\beta=(X'X)^{-1}X'y\]となります.
この $\beta$ を最小2乗推定量(OLS estimation)といいます.
ここで,$x$ の平均は $E(x)$ なので,\[(y-\beta_{1}-\beta_{2}x)\]という式は,\[(y-\beta_{1}-\beta_{2}x+\beta_{2}E(x)-\beta_{2}E(x))\]と変形出来ます.
この式を整理すると,\[(y-\beta_{1}-\beta_{2}(x-E(x))-\beta_{2}E(x))\]となります.
この式の期待値をとると,\[E(y-\beta_{1}-\beta_{2}(x-E(x))-\beta_{2}E(x))\]となりますので,さらに変形して,\[E(y)-E(\beta_{1})-E(\beta_{2}x)+E(\beta_{2}E(x))-E(\beta_{2}E(x))\]となり,\[E(y)-\beta_{1}-\beta_{2}E(x)+\beta_{2}E(x)-\beta_{2}E(x)\]つまり,\[E(y)-\beta_{1}-\beta_{2}E(x)\]となるので,\[E(y)-\beta_{1}-\beta_{2}E(x)=0\]から,\[\beta_{1}=E(y)-\beta_{2}E(x)\]となります.
続いて,\[y-\beta_{1}-\beta_{2}x=0\]であることから,\[(x-E(x))(y-\beta_{1}-\beta_{2}x)=0\]となるので,ここに,\[\beta_{1}=E(y)-\beta_{2}E(x)\]を代入すると,\[(x-E(x))(y-(E(y)-\beta_{2}E(x))-\beta_{2}x)=0\]つまり,\[(x-E(x))(y-E(y)+\beta_{2}E(x)-\beta_{2}x)=0\]となるので,さらに,\[(x-E(x))(y-E(y)+\beta_{2}(E(x)-x))=0\]そして,\[(x-E(x))(y-E(y))+(x-E(x))(\beta_{2}(E(x)-x))=0\]となるので,\[(x-E(x))(y-E(y))-\beta_{2}(E(x)-x)^{2}=0\]すなわち,\[\beta_{2}=\frac{(x-E(x))(y-E(y))}{(E(x)-x)^{2}}\]となるので,結局,$\beta_{1},\beta_{2}$ は,\[\begin{align}\beta_{1}&=E(y)-\beta_{2}E(x)\\\beta_{2}&=\frac{E[\{x-E(x)\}\{y-E(y)\}]}{E[\{x-E(x)\}^{2}]}\end{align}\]となります.
# coding: utf-8
from __future__ import division
#Python 2.7でimportをすればPython 3風に,Python 2.7では割り算「/」の結果は切り捨てでしたが
#Python 3以降ではちゃんと小数点以下まで保持されるようになります
from matplotlib import pyplot as plt
import numpy as np
def main():
# データ点数は 100 にする
N = 100
# 0 ~ 30 (-15 ~ +15) の範囲で,ランダムに値を散らばらせる
R = 30
#N個のデータを生成して x に代入
x = np.arange(N)
# y = 50 + x の直線に (-5 ~ +5) でランダム性をもたせる
#0x@Ρの一様乱数をN個生成する
y = np.arange(N) + np.random.rand(N) * R - R // 2 + 50
# 平均値と標準偏差
xmean, xsigma2 = x.mean(), x.var()
# 平均値
ymean = y.mean()
# 共分散
sxy = np.sum(x * y) / N - xmean * ymean
# 回帰係数ベータ
beta = sxy / xsigma2
# 回帰係数アルファ
alpha = ymean - beta * xmean
# 得られた回帰直線の一次式
print('y = {0} + {1}x'.format(alpha, beta))
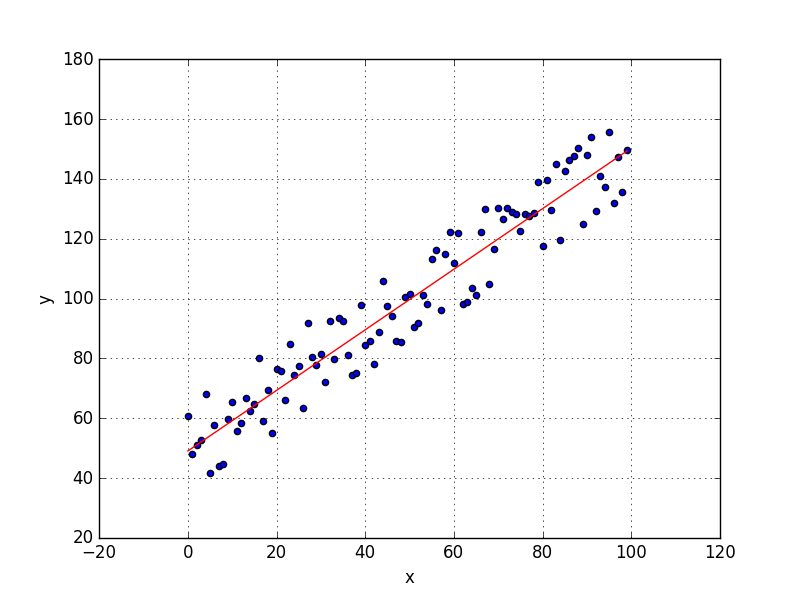
# グラフに回帰直線をひく
ols = np.array([alpha + beta * xi for xi in x])
plt.plot(x, ols, color='r')
# 元データもプロットする
plt.scatter(x, y)
# グラフを表示する
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.show()
if __name__ == '__main__':
main()

Mathematics is the language with which God has written the universe.